在将您的策略开始实时模拟交易/实盘交易之前,滚动优化回测绝对是您应该关注的最后一项测试。
很多人应该都有过用超参数优化让初始策略的收益翻好几倍的经历。这看起来很不错,然而当你面对这样一份非常漂亮的回测报告时,你到底有多大把握这组参数在未来的一段时间依然能取得较好收益呢?
不光基于机器学习、神经网络的交易策略容易过拟合,基于传统指标并进行超参数优化也很有可能得到过拟合后的参数。
事实上,当你使用固定周期的回测报告来假设未来收益时,你就已经犯了错误!
我们始终应该基于新的数据来进行回测。如果你有3年的数据,可以用前两年进行超参数优化得到一组参数,对后1年进行回测。
在现实世界中,我们可能更希望每隔几个月进行一次超参数优化,避免因行情变化而持续亏损,所以更符合现实的方案可能是:如果我们有最近3年的数据,先用最早第1年的数据进行超参数优化,使用优化后的参数对接下来的2个月进行回测;然后推迟2个月取1年的数据继续超参数优化,重复对后2个月进行回测,如此滚动,我们最终可以得到最近2年的不含未来信息的一组回测报告。
在banbot中,您只需要使用下面命令就可实现这一过程:
banbot.o bt_opt -review-period 12M -run-period 2M -opt-rounds 20 -picker score滚动优化回测结束后,我们会得到一个包含每次优化日志的文件夹:
图中的每个log文件即是一次超参数优化的日志,我们打开第一个看下结果:
# run hyper optimize: bayes, rounds: 20
# date range: 2021-01-01 00:00:00 - 2021-12-27 00:00:00
============== freqtrade:Strategy001/5m/ =============
loss: -81.15 bigRate: 2.02, lenSml: 19.49, midRate: 2.38 odNum: 195, profit: 109.7%, drawDown: 18.2%, sharpe: 6.89
loss: -86.14 bigRate: 2.00, lenSml: 20.71, midRate: 3.72 odNum: 292, profit: 107.8%, drawDown: 13.9%, sharpe: 7.69
loss: -118.02 bigRate: 2.15, lenSml: 20.92, midRate: 2.71 odNum: 210, profit: 167.9%, drawDown: 20.9%, sharpe: 7.49
loss: -72.20 bigRate: 1.90, lenSml: 20.89, midRate: 2.52 odNum: 220, profit: 100.6%, drawDown: 19.8%, sharpe: 6.73
loss: -80.40 bigRate: 2.17, lenSml: 22.64, midRate: 1.96 odNum: 148, profit: 115.2%, drawDown: 21.3%, sharpe: 6.66
loss: -90.39 bigRate: 1.88, lenSml: 23.61, midRate: 2.79 odNum: 183, profit: 164.5%, drawDown: 32.9%, sharpe: 5.15
loss: -93.75 bigRate: 1.84, lenSml: 16.12, midRate: 2.43 odNum: 247, profit: 126.3%, drawDown: 18.0%, sharpe: 7.04
loss: -72.83 bigRate: 1.98, lenSml: 19.76, midRate: 3.77 odNum: 293, profit: 91.1%, drawDown: 13.9%, sharpe: 6.80
loss: -71.02 bigRate: 1.93, lenSml: 19.75, midRate: 3.89 odNum: 304, profit: 97.6%, drawDown: 19.1%, sharpe: 6.64
loss: -140.38 bigRate: 2.61, lenSml: 27.93, midRate: 3.90 odNum: 192, profit: 191.3%, drawDown: 18.6%, sharpe: 8.48
loss: -95.02 bigRate: 2.88, lenSml: 23.35, midRate: 2.77 odNum: 192, profit: 165.0%, drawDown: 30.8%, sharpe: 8.92
loss: -78.63 bigRate: 2.02, lenSml: 29.28, midRate: 3.28 odNum: 212, profit: 109.3%, drawDown: 19.7%, sharpe: 6.81
loss: -81.46 bigRate: 2.69, lenSml: 21.28, midRate: 3.71 odNum: 258, profit: 109.1%, drawDown: 17.7%, sharpe: 7.20
# score: 140.38
- name: freqtrade:Strategy001
run_timeframes: [ 5m ]
params: {bigRate: 2.61, lenSml: 27.93, midRate: 3.90}由于搜索空间较小,贝叶斯进行了13次迭代后终止了,然后banbot自动选择了分数最高(即loss最小)的一组参数用于后续2个月回测。
如此迭代,最后banbot会自动将所有2个月的间隔回测结果组合,形成单个回测报告:
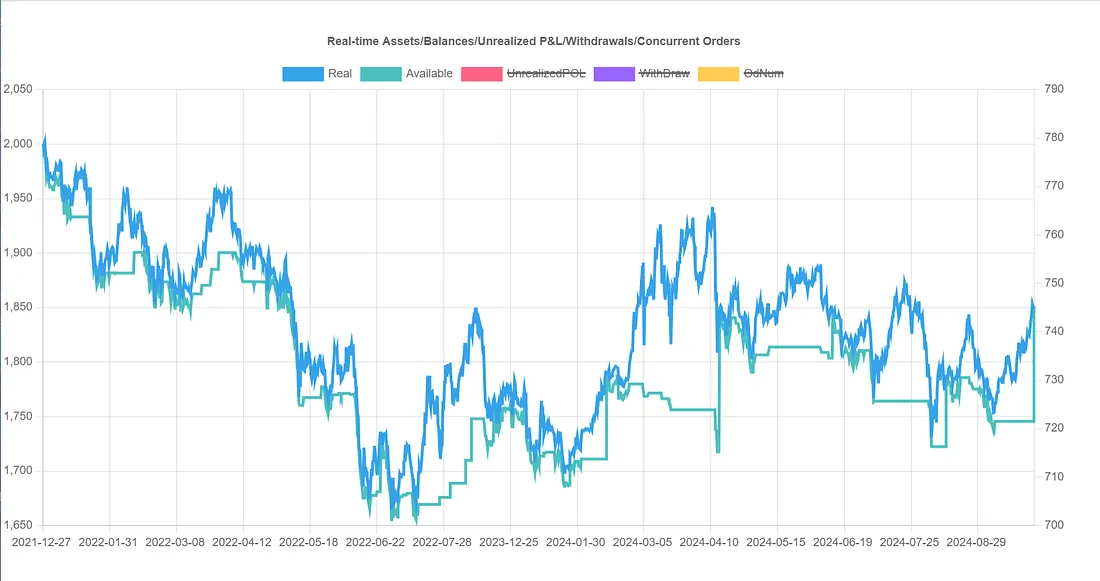
从组合报告来看,它的整体收益是-7%,甚至远差于最初策略的7%收益;所以超参数优化的分数最高的参数组在未来一段时间收益比初始参数还差!也就是说它出现了过拟合!
如何避免过拟合呢?或许可以将所有收益为正的参数组取平均值,用于回测后2个月?让我们试一下滚动优化测试(我们只需要将picker从score改为goodAvg):
banbot.o bt_opt -review-period 12M -run-period 2M -opt-rounds 20 -picker goodAvg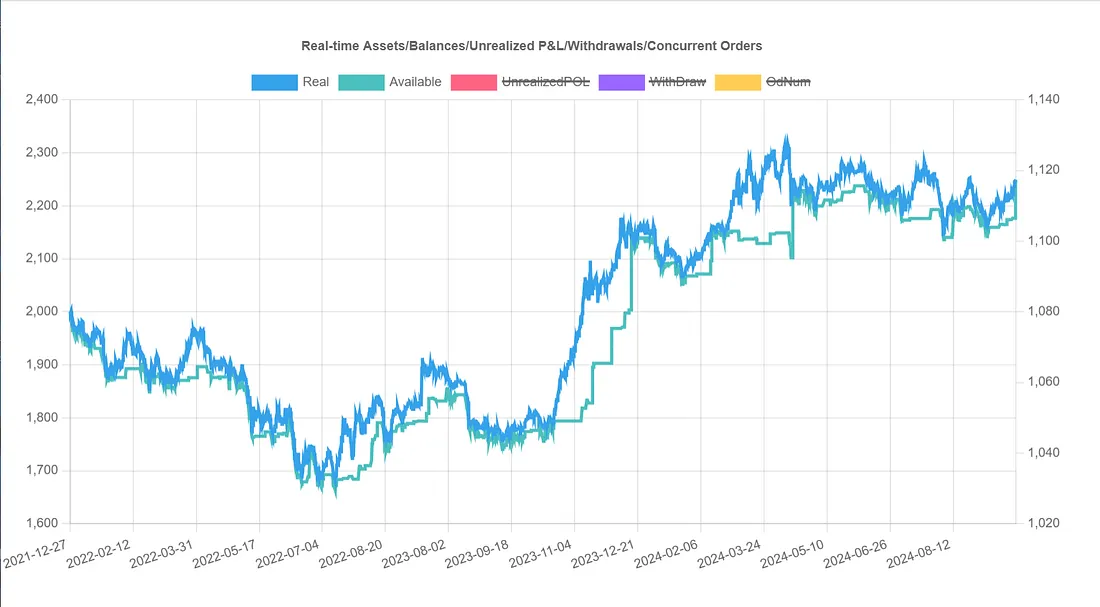
这个改动取得了很好的结果,累计收益12.4%,远高于最初策略的7%收益!那如果我们使用其他方式从超参数优化结果选择参数组,效果会更好吗?
我们可以依然用滚动测试的方法,对banbot内置的几个挑选器进行测试,将不同挑选器2个月的回测分数进行比较,我们应该可以得到17组分数:
banbot.o tool test_pickers -review-period 12M -run-period 2M -opt-rounds 20执行结束后,我们可以在输出目录得到一个pickerScores.csv文件,让我们用excel打开,然后绘制一个折线图: 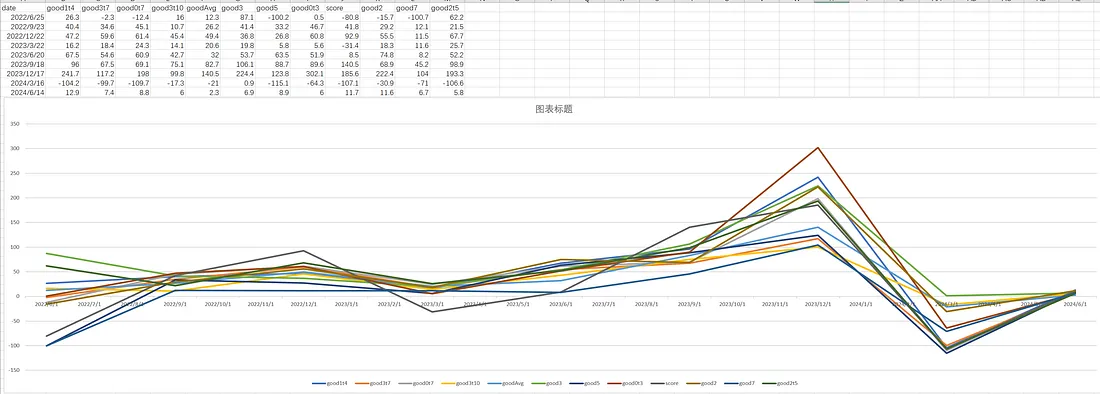
注意
由于Strategy001对不同picker分数差异不明显,此图表是基于其他策略测试pickers后得到的。
我们评估的依据应当是优先选择在保持低回撤的情况下,尽可能多的盈利。 从图表上看,good3是最符合的,即将超参数优化结果按分数降序,过滤掉亏损的,取盈利的30%位置的一组参数。这也是banbot的默认picker。
这也应该符合我们的基本直觉:选择盈利的参数,但不能选分数最高的避免过拟合。