banbot.o optimize -out PATH [-opt-rounds 30] [-sampler bayes]您在策略中使用pol.Def定义好超参数及其范围后,您可以对其进行超参数调优。
启动时您需要指定一个输出文件,超参数搜索结果将写入到此文件中,一般形如opt1.log。 您可通过-opt-rounds指定调优的执行次数,以及-sampler指定采样优化器。调优时将固定使用-nodb参数。
如果您有多组策略需要优化,默认情况下banbot将逐个搜索每个策略;如果您希望提高并发,可编译为可执行文件后,传入-concur参数控制并发数量。
您可使用-picker指定一个挑选器名称,用于从搜索结果中选择一组参数。未指定时,默认使用good3
Usage of optimize:
-concur int
Concurrent Number (default 1)
-config value
config path to use, Multiple -config options may be used
-datadir string
Path to data dir.
-each-pairs
run for each pairs
-level string
set logging level to debug (default "info")
-logfile string
Log to the file specified
-max-pool-size int
max pool size for db
-no-compress
disable compress for hyper table
-no-default
ignore default: config.yml, config.local.yml
-nodb
dont save orders to database
-opt-rounds int
rounds num for single optimize job (default 30)
-out string
output file or directory
-picker string
Method for selecting targets from multiple hyperparameter optimization results (default "good3")
-sampler string
hyper optimize method, tpe/bayes/random/cmaes/ipop-cmaes/bipop-cmaes (default "bayes")完成超参数优化后,您打开输出文件可看到日志:
# run hyper optimize: bayes, rounds: 20
# date range: 2021-01-01 00:00:00 - 2021-12-27 00:00:00
============== freqtrade:Strategy001/5m/ =============
loss: -81.15 bigRate: 2.02, lenSml: 19.49, midRate: 2.38 odNum: 195, profit: 109.7%, drawDown: 18.2%, sharpe: 6.89
loss: -86.14 bigRate: 2.00, lenSml: 20.71, midRate: 3.72 odNum: 292, profit: 107.8%, drawDown: 13.9%, sharpe: 7.69
loss: -118.02 bigRate: 2.15, lenSml: 20.92, midRate: 2.71 odNum: 210, profit: 167.9%, drawDown: 20.9%, sharpe: 7.49
loss: -72.20 bigRate: 1.90, lenSml: 20.89, midRate: 2.52 odNum: 220, profit: 100.6%, drawDown: 19.8%, sharpe: 6.73
loss: -80.40 bigRate: 2.17, lenSml: 22.64, midRate: 1.96 odNum: 148, profit: 115.2%, drawDown: 21.3%, sharpe: 6.66
loss: -90.39 bigRate: 1.88, lenSml: 23.61, midRate: 2.79 odNum: 183, profit: 164.5%, drawDown: 32.9%, sharpe: 5.15
loss: -93.75 bigRate: 1.84, lenSml: 16.12, midRate: 2.43 odNum: 247, profit: 126.3%, drawDown: 18.0%, sharpe: 7.04
loss: -72.83 bigRate: 1.98, lenSml: 19.76, midRate: 3.77 odNum: 293, profit: 91.1%, drawDown: 13.9%, sharpe: 6.80
loss: -71.02 bigRate: 1.93, lenSml: 19.75, midRate: 3.89 odNum: 304, profit: 97.6%, drawDown: 19.1%, sharpe: 6.64
loss: -140.38 bigRate: 2.61, lenSml: 27.93, midRate: 3.90 odNum: 192, profit: 191.3%, drawDown: 18.6%, sharpe: 8.48
loss: -95.02 bigRate: 2.88, lenSml: 23.35, midRate: 2.77 odNum: 192, profit: 165.0%, drawDown: 30.8%, sharpe: 8.92
loss: -78.63 bigRate: 2.02, lenSml: 29.28, midRate: 3.28 odNum: 212, profit: 109.3%, drawDown: 19.7%, sharpe: 6.81
loss: -81.46 bigRate: 2.69, lenSml: 21.28, midRate: 3.71 odNum: 258, profit: 109.1%, drawDown: 17.7%, sharpe: 7.20
# score: 140.38
- name: freqtrade:Strategy001
run_timeframes: [ 5m ]
params: {bigRate: 2.61, lenSml: 27.93, midRate: 3.90}过拟合陷阱
超参数优化不是魔法,它本质上是在一段时间的数据上测试策略的不同参数,找出收益较好的参数。
我们都知道基于机器学习和神经网络的交易策略非常容易过拟合,即在训练数据上表现优异,但在测试数据上收益很差。
超参数优化和上面过程类似,用于搜索参数的数据可以看做训练数据,我们选择训练数据上表现最好的一组参数,它很难说在未来一段时间继续有较好的收益(事实上,反而亏损)。
这就是因为训练数据表现最好的这组参数出现了过拟合。
为了避免过拟合,我们需要某种方式从搜索记录中得到在未来一段时间表现最好的参数,banbot提供了-picker参数实现这一目的。
banbot内置的picker有:
- score: 选择分数最高的(loss最低的)
- good3: 筛选盈利的组按分数降序,取从前往后位置在30%的一组参数。
- good0t3: 筛选盈利的组按分数降序,对前30%的所有组,取平均值得到一组参数。
- goodAvg: 队所有盈利的组取平均值得到一组参数。
- good1t4: 筛选盈利的组按分数降序,对前10%~40%的所有组,取平均值得到一组参数。
- good4: 筛选盈利的组按分数降序,取从前往后位置在40%的一组参数。
- good2: 筛选盈利的组按分数降序,取从前往后位置在20%的一组参数。
- good5: 筛选盈利的组按分数降序,取从前往后位置在50%的一组参数。
- good7: 筛选盈利的组按分数降序,取从前往后位置在70%的一组参数。
- good2t5: 筛选盈利的组按分数降序,对前20%~50%的所有组,取平均值得到一组参数。
- good3t7: 筛选盈利的组按分数降序,对前30%~70%的所有组,取平均值得到一组参数。
- good0t7: 筛选盈利的组按分数降序,对前70%的所有组,取平均值得到一组参数。
- good3t10: 筛选盈利的组按分数降序,对前30%之后的所有组,取平均值得到一组参数。
您可以使用banbot.o tool test_pickers测试所有picker在未来回测时的分数。
我们经过多次测试后发现good3在大多数情况下略好于其他挑选器。 比good3略差一点的是:good0t3/goodAvg/good1t4/good4; 其他挑选器大多数情况下效果一般或较差。
这是在某组策略上通过tool test_pickers测试得到的不同picker表现:
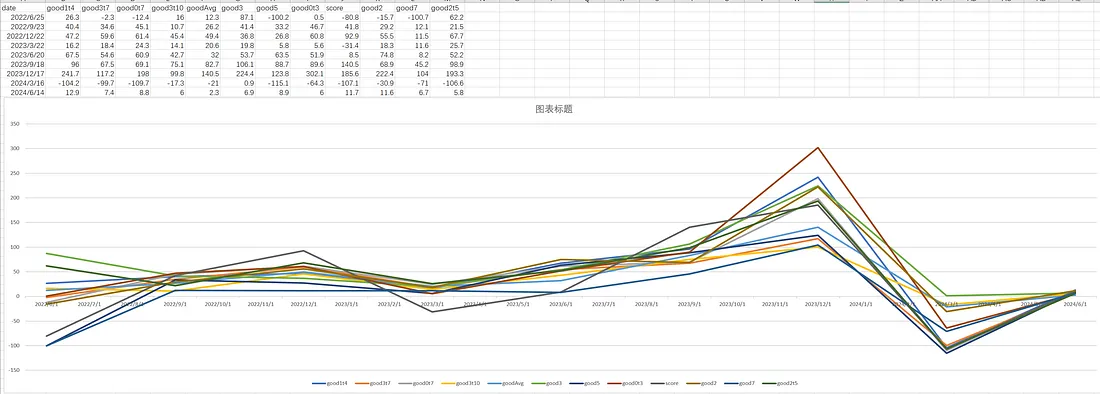
如果您不确定您的回测报告是否过拟合,强烈推荐您使用滚动优化回测!